数据结构
线性表
线性表是由n(n>=0)个属于同一个数据对象的数据元素a1,a2,a3...an-1,an组成的有序列。在计算机内部可以采用不同方式存储一个线性表,其中最简单的方式就是用一组地址连续的存储单元来依次存储线性表中的数据元素。这种存储结构称为 线性表的顺序存储结构 ,此时称为顺序表;还有一种线性表的存储结构——链式存储结构,也称为线性链表或者单链表。
C语言示例:
#include <stdio.h>
#include <stdlib.h>
typedef struct node
{
int data;
struct node *link;
} node, *linklist;
linklist create(int data);
int length(linklist list);
int isEmpty(linklist list);
linklist find(linklist list, int data);
void prependNode(linklist *list, int data);
void appendNode(linklist list, int data);
void insertAfterNode(linklist list, node *pos, int data);
int insertAfterIndex(linklist list, int pos, int data);
void deleteNode(linklist *list, int data);
void deleteLinkList(linklist list);
void reverse(linklist *list);
void join(linklist lista, linklist listb);
void printLinkList(linklist list);
// 具体实现
linklist create(int data)
{
linklist list;
list = (linklist)malloc(sizeof(node));
list->data = data;
list->link = NULL;
return list;
}
int length(linklist list)
{
int len = 0;
linklist p = list;
while(p != NULL){
len ++;
p = p->link;
}
return len;
}
int isEmpty(linklist list)
{
return list == NULL;
}
linklist find(linklist list, int data)
{
linklist p;
p = list;
while(p!=NULL && p->data != data)
p = list->link;
return p;
}
void prependNode(linklist *list, int data)
{
linklist p;
p = (linklist)malloc(sizeof(node));
p->data = data;
p->link = *list;
*list = p;
}
void appendNode(linklist list, int data)
{
linklist p, new;
new = (linklist) malloc (sizeof(node));
new->data = data;
new->link = NULL;
p = list;
while (p->link != NULL)
p = p->link;
p->link = new;
}
void printLinkList(linklist list)
{
linklist p;
if(list == NULL){
printf("NULL\n");
return;
}
p = list;
while (p != NULL)
{
printf("%d->", p->data);
p = p->link;
}
printf("NULL\n");
}
void insertAfterNode(linklist list, node *pos, int data)
{
linklist p = (linklist) malloc(sizeof(node));
if(list == NULL){
list = p;
list->link = NULL;
} else {
p->link = pos->link;
pos->link = p;
}
}
int insertAfterIndex(linklist list, int pos, int data)
{
linklist p = list, new;
int j = 0;
while(j < pos && p != NULL)
{
p = p->link;
j++;
}
if(j != pos || p == NULL)
{
printf("can not find the %dth node\n", pos);
return 0;
}
new = (linklist) malloc(sizeof(node));
new->link = p->link;
new->data = data;
p->link = new;
return 1;
}
void deleteNode(linklist *list, int data)
{
linklist p = *list, tmp, d;
if(p->data == data){
*list = p->link;
free(p);
}
p = *list;
tmp = p;
while(tmp != NULL && tmp->link != NULL)
{
if(tmp->link->data == data){
d = tmp->link;
tmp->link = d->link;
free(d);
}
tmp = tmp->link;
}
}
void deleteLinkList(linklist list)
{
linklist p, tmp;
p = list;
while(p != NULL){
tmp = p->link;
printf(">>>>p->data: %d\n", p->data);
free(p);
p = NULL;
p = tmp;
}
list = NULL;
}
void reverse(linklist *list)
{
linklist p = *list;
linklist prev = NULL;
linklist tmp;
while(p != NULL){
tmp = prev;
prev = p;
p = p->link;
prev->link = tmp;
}
*list = prev;
}
void join(linklist lista, linklist listb)
{
linklist tail = lista;
while(tail->link != NULL){
tail = tail->link;
}
tail->link = listb;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
堆栈
堆栈(stack)简称栈,它是一种只允许在表的一段进行插入和删除操作的线性表。允许操作的一端称为栈顶,栈顶元素的位置由一个称为栈顶指针的变量给出,另一端称为栈低。当表中没有元素时,称之为空栈。堆栈的插入操作简称为入栈或者进栈,删除操作称为出栈或者退栈。
一般将采用顺序存储结构的堆栈简称为顺序堆栈,可以利用一个具有M个元素的数组来描述。这种堆栈的优点是可以节省空间,但是当存储空间即将充满时,需要移动大量的数据元素到新的数组中。堆栈还有另外一种存储方式——堆栈的链式存储,称之为链接堆栈, 简称链栈。
C实现链栈:
#include <stdio.h>
#include <stdlib.h>
typedef struct stackNode
{
int data;
struct stackNode *next;
} stackNode;
typedef struct stack
{
stackNode *top;
int size;
} stack;
stack *stackInit();
int isEmpty(stack *s);
int stackGet(stack *s);
int stackPop(stack *s);
int stackPush(stack *s, int data);
void stackPrint(stack *s);
stack *stackInit()
{
stack *s = malloc(sizeof(stack));
s->top = NULL;
s->size = 0;
return s;
}
int isEmpty(stack *s)
{
if(s == NULL || s->size == 0)
return 1;
return 0;
}
int stackPush(stack *s, int data)
{
stackNode *node = malloc(sizeof(stackNode));
node->data = data;
node->next = NULL;
if(s->top == NULL)
s->top = node;
else {
node->next = s->top;
s->top = node;
}
s->size++;
return s->size;
}
void stackPrint(stack *s)
{
if(s->size == 0)
return;
stackNode *node;
node = s->top;
while(node != NULL){
printf(" %d ", node->data);
node = node->next;
}
printf("\n");
}
int stackPop(stack *s)
{
if(s->size < 1){
printf("Error: stack is empty!\n");
exit(0);
}
int data = s->top->data;
stackNode *node = s->top->next;
free(s->top);
s->top = node;
return data;
}
int stackGet(stack *s)
{
if (s->size < 1){
printf("Error: stack is empty!\n");
exit(0);
}
return s->top->data;
}
// int main(int argc, char const *argv[])
// {
// stack *s = stackInit();
// printf("s is empty ? %s \n", isEmpty(s) ? "Y" : "N");
// stackPush(s, 1);
// stackPush(s, 2);
// stackPush(s, 3);
// printf("s is empty ? %s \n", isEmpty(s) ? "Y" : "N");
// stackPrint(s);
// printf("Pop out %d\n", stackPop(s));
// stackPrint(s);
// return 0;
// }
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
队列
队列(queue),简称队,是一种只允许在表的一端进行插入操作,而在表的另一端进行删除操作的线性表。元素进入队列或者退出队列都是按照“先进先出(First In first Out,FIFO)”的原则进行的,因此,队列也称为先进先出表。
C 数组实现:
#include <stdio.h>
#include <stdlib.h>
#include <limits.h>
#define ERR 0
#define OK 1
typedef struct Queue
{
int front, rear, size;
unsigned capacity;
int * array;
} Queue;
Queue *createQueue(unsigned capacity);
int isFull(Queue *queue);
int isEmpty(Queue *queue);
int enqueue(Queue *queue, int item);
int dequeue(Queue *queue);
int front(Queue *queue);
int rear(Queue *queue);
void printQueue(Queue *queue);
Queue *createQueue(unsigned capacity)
{
Queue *queue = (Queue *) malloc(sizeof(Queue));
queue->capacity = capacity;
queue->front = queue->size = 0;
queue->rear = capacity - 1;
queue->array = (int *)malloc(queue->capacity * sizeof(int));
return queue;
}
int isFull(Queue *queue)
{
return (queue->size == queue->capacity);
}
int isEmpty(Queue *queue)
{
return queue->size == 0;
}
int enqueue(Queue *queue, int item)
{
if(isFull(queue))
return ERR;
queue->rear = (queue->rear + 1) % queue->capacity;
queue->array[queue->rear] = item;
queue->size = queue->size + 1;
printf("%d enqueued to queue\n", item);
return OK;
}
int dequeue(Queue *queue)
{
int item;
if(isEmpty(queue))
return INT_MIN;
item = queue->array[queue->front];
queue->front = (queue->front + 1) % queue->capacity;
queue->size--;
printf("%d dequeue from queue\n", item);
return item;
}
int rear(Queue *queue)
{
if(isEmpty(queue))
return INT_MIN;
return queue->array[queue->rear];
}
int front(Queue *queue)
{
if(isEmpty(queue))
return INT_MIN;
return queue->array[queue->front];
}
void printQueue(Queue *queue)
{
if(isEmpty(queue)){
printf("Empty queue\n");
return;
}
int idx = queue->front;
while(idx != queue->rear){
printf("%d->", queue->array[idx]);
idx = (idx + 1) % queue->capacity;
}
printf("%d\n", queue->array[idx]);
}
int main(int argc, char const *argv[])
{
Queue *queue = createQueue(3);
enqueue(queue, 1);
printQueue(queue);
enqueue(queue, 2);
printQueue(queue);
enqueue(queue, 3);
printQueue(queue);
dequeue(queue);
printQueue(queue);
dequeue(queue);
printQueue(queue);
dequeue(queue);
printQueue(queue);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
C 链表实现:
#include <stdio.h>
#include <stdlib.h>
typedef struct QNode
{
int key;
struct QNode *next;
} QNode;
typedef struct Queue
{
QNode *front, *rear;
} Queue;
QNode *newNode(int k);
Queue *createQueue();
void enQueue(Queue *q, int k);
QNode *deQueue(Queue *q);
void printQueue(Queue *q);
QNode *newNode(int k)
{
QNode *tmp = (QNode *) malloc(sizeof(QNode));
tmp->key = k;
tmp->next = NULL;
return tmp;
}
Queue *createQueue()
{
Queue *q = (Queue *) malloc(sizeof(Queue));
q->front = q->rear = NULL;
return q;
}
void enQueue(Queue *q, int k)
{
QNode *tmp = newNode(k);
if(q->rear == NULL){
q->rear = q->front = tmp;
return;
}
q->rear->next = tmp;
q->rear = tmp;
}
QNode *deQueue(Queue *q)
{
if(q->front == NULL)
return NULL;
QNode *tmp;
tmp = q->front;
q->front = q->front->next;
if(q->front == NULL)
q->rear = NULL;
return tmp;
}
void printQueue(Queue *q)
{
if(q->front == NULL){
printf("Empty queue\n");
return;
}
QNode *tmp = q->front;
while(tmp != NULL){
printf("%d", tmp->key);
tmp = tmp->next;
if(tmp != NULL)
printf("->");
}
printf("\n");
}
int main()
{
Queue *q = createQueue();
enQueue(q, 10);
printQueue(q);
enQueue(q, 20);
printQueue(q);
deQueue(q);
printQueue(q);
deQueue(q);
printQueue(q);
enQueue(q, 30);
printQueue(q);
enQueue(q, 40);
printQueue(q);
enQueue(q, 50);
printQueue(q);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
广义表
在一个线性表A中,每个数据元素只限于是结构上不可再分割的原子元素,而不能是其他情况,如果放宽这个限制,允许表中的元素即可是原子元素,也可以是另外一个表,则称这样的表为广义表。 设ai为广义表的第i个元素,则广义表GL的一般表示与线性表相同: GL=(a1,a2,…,ai,…,an)
其中n表示广义表的长度,即广义表中所含元素的个数,n≥0。如果ai是单个数据元素,则ai是广义表GL的原子;如果ai是一个广义表,则ai是广义表GL的子表。
广义表具有如下重要的特性:
- 广义表中的数据元素有相对次序;
- 广义表的长度定义为最外层包含元素个数;
- 广义表的深度定义为所含括弧的重数。其中原子的深度为0,空表的深度为1;
- 广义表可以共享;一个广义表可以为其他广义表共享;这种共享广义表称为再入表;
- 广义表可以是一个递归的表。一个广义表可以是自已的子表。这种广义表称为递归表。递归表的深度是无穷值,长度是有限值;
- 任何一个非空广义表GL均可分解为表头head(GL) = a1和表尾tail(GL) = ( a2,…,an) 两部分。
另外,我们规定用小写字母表示原子,用大写字母表示广义表的表名。例如:
A=()
B=(e)
C=(a,(b,c,d))
D=(A,B,C)=((),(e),(a,(b,c,d)))
E=((a,(a,b),((a,b),c)))
2
3
4
5
其中A是一个空表,其长度为0; B是只含有单个原子e的表,其长度为1; C有两个元素,一个是原子a,另一个是子表,其长度为2; D有三个元素,每个元素都是一个表,其长度为3; E中只含有一个元素,是一个表,它的长度为1。
广义表是一种递归的数据结构,因此很难为每个广义表分配固定大小的存储空间,所以其存储结构只好采用动态链式结构。
C 实现:
#include <stdio.h>
#include <stdlib.h>
typedef struct node {
int flag; /* 标志域:0时data存放原子元素数据,1时pointer存放子表第一个元素地址 */
union
{
int data;
struct node *pointer;
};
struct node *link; /* 同一层的元素通过link链接为一个线性链表 */
} node;
2
3
4
5
6
7
8
9
10
11
12
13
串
串是由n(n>=0)个字符组成的有序序列,通常记作: S = 'a1,a2,…,ai,…,an'。
树
树(tree)是由n(n>=0)个结点组成的有穷集合(D)与在D上关系的集合R构成的结构,记成T。
- 基本术语
- 结点的度 结点拥有的子树数目称为该结点的度。
- 树的度 树中各结点度的最大值被定义为该树的度。
- 叶子结点 度为0的结点被称为分支节点或者终端结点,简称为叶结点。
- 分支结点 度不为0的结点称为分支结点或者非终端结点。
- 结点的层次 从根结点所在开始,根结点为第1层,根节点的孩子结点为第2层,以此类推。
- 树的深度 树中结点的最大层次数被定义为该树的深度或者高度。
- 有序树 若树中结点子树的相对次序不能随意变换,或者说改变前后的树表示的不是同一个对象,则称该树为有序树。
- 森林 m(m>=0)棵不相交的树的集合被称为森林或者树林。对树中的每个分支结点来说,其子树的集合就是一个森林。
- 树的性质
- 性质一 非空树的结点总数等于树中所有结点的度之和加1。
- 性质二 度为K的非空树的第i层最多有ki-1个结点(i>=1)。(数学归纳法证明)
- 性质三 深度为h的k叉树最多有(kh - 1) / (k - 1)个结点。该树称为满K叉树,
- 性质四 具有n个结点的k叉树的最小深度为[logk(n(k-1) + 1)]。
二叉树
二叉树是n(n>=0)个结点的有穷集合D与D上关系集合R构成的结构。当n=0时为空二叉树,否则它便是包含了一个根结点以及两棵不相交的、分别称为左子树和右子树的二叉树。一般称左子树的根结点为该分支结点的左孩子,右子树的根结点称作该分支结点的右孩子。
- 两种特殊形态的二叉树
- 一棵深度为h且有2h - 1个结点的二叉树就是满二叉树。
- 若二叉树中最多只有最下面的两层结点的度可以小于2,并且最下面的结点(叶结点)都依次排列在该层最左边的位置上,具有这样的特定的二叉树称为完全二叉树。
- 二叉树的性质
- 性质一 具有n个结点的非空二叉树有且仅有n-1个分支。
- 性质二 非空二叉树的第i层最多有2n-1个结点
- 性质三 深度为h的非空二叉树最多有2h - 1个结点
- 性质四 在任意非空二叉树中,若叶结点的数目为n0,度为2的结点数目为n2,则关系有n0 = n2 + 1。
- 性质五 具有n(n>0)个结点的完全二叉树的深度为h = (log2n) + 1。
- 性质六 如果对一棵有n个结点的完全二叉树的结点按层序编号(从第一层到最后一层,每层从左到右),对任一结点i(1<=i<=n)有:
- 如果i=1,则结点i是二叉树的根,无双亲;如果i>1,则其双亲是结点 ⌊ i/2 ⌋ 。
- 如果2i>n,则结点i无左孩子(结点i为叶子结点);否则其左孩子是结点2i 。
- 如果2i+1>n,则结点i无右孩子;否则其右孩子是结点2i+1 。
C 示例1:由广义表形式建立相应的二叉链表结构
/**
* A
* / \
* B c
* / \ /
* D E F
* / \
* G H
*
* 对于上面这棵树,可以表示成: A(B(D,E),C(F(,H)))@
* “@”表示结束。如何由上述的广义表形式建立相应的二叉链表结构呢?
*/
#include <stdio.h>
#include <stdlib.h>
typedef struct BTree
{
char data;
struct BTree *ltree, *rtree;
} BTree;
BTree *createBinaryTreeFromString(char *btree_string);
void preOrderPrint(BTree *bt);
BTree *createBinaryTreeFromString(char *btree_string)
{
char *c = btree_string;
BTree *STACK[1024], *root, *node, *p;
int flag = 0, top = -1;
while(*c)
{
switch(*c){
case '(':
flag = 1; // left tree
STACK[++top] = p;
break;
case ')':
--top;
break;
case ',':
flag = 2; // right tree
break;
case '@':
return root;
break;
default:
p = (BTree *)malloc(sizeof(BTree));
p->data = *c;
p->ltree = NULL;
p->rtree = NULL;
if(flag == 0)
root = p;
else if(flag == 1)
STACK[top]->ltree = p;
else if(flag == 2)
STACK[top]->rtree = p;
}
c++;
}
return root;
}
void preOrderPrint(BTree *bt)
{
if(bt == NULL){
return;
}
printf("%c\t", bt->data);
preOrderPrint(bt->ltree);
preOrderPrint(bt->rtree);
}
int main()
{
char *p = "A(B(D,E(G)),C(F(,H)))@";
BTree *bt = createBinaryTreeFromString(p);
preOrderPrint(bt);
return 1;
}2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
C 示例2:由顺序列表存储结构建立相应的二叉链表结构
/**
*
* 已知非空二叉树采用顺序存储结构,结点的数据信息依次存放在数组BT[0..MaxN - 1]中(若元素值为0,
* 表示该元素对应的结点在二叉树中不存在)。写出该二叉树的二叉链表结构的算法。
*
*/
#include <stdio.h>
#include <stdlib.h>
#define MaxN 15
typedef struct BTree
{
int data;
struct BTree *ltree, *rtree;
} BTree;
BTree *createBinaryTreeFromArray(int *BT);
void preOrderPrint(BTree *bt);
BTree *createBinaryTreeFromArray(int *BT)
{
BTree *root, *p[MaxN];
int i, j;
p[0] = malloc(sizeof(BTree));
p[0]->data = BT[0];
p[0]->ltree = NULL;
p[0]->rtree = NULL;
root = p[0];
for(i = 1; i < MaxN; i++)
{
if(BT[i] != 0){
p[i] = malloc(sizeof(BTree));
p[i]->data = BT[i];
p[i]->ltree = NULL;
p[i]->rtree = NULL;
j = (i - 1) / 2;
if(i - j * 2 - 1 == 0)
p[j]->ltree = p[i];
else
p[j]->rtree = p[i];
}
}
return root;
}
void preOrderPrint(BTree *bt)
{
if (bt == NULL)
{
return;
}
printf("%d\t", bt->data);
preOrderPrint(bt->ltree);
preOrderPrint(bt->rtree);
}
int main(int argc, char const *argv[])
{
int BT[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15};
BTree *bt = createBinaryTreeFromArray(BT);
preOrderPrint(bt);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
C 示例3:二叉链表存储结构的二叉树的结点数目和树的深度,树的遍历
/**
* A
* / \
* B c
* / \ /
* D E F
* / \
* G H
*
* 对于上面这棵树,可以表示成: A(B(D,E),C(F(,H)))@
* “@”表示结束。如何由上述的广义表形式建立相应的二叉链表结构呢?
*/
#include <stdio.h>
#include <stdlib.h>
typedef struct BTree
{
char data;
struct BTree *ltree, *rtree;
} BTree;
BTree *createBinaryTreeFromString(char *btree_string);
void preOrderPrint(BTree *bt);
int countLeaf(BTree *bt);
int treeDepth(BTree *bt);
BTree *createBinaryTreeFromString(char *btree_string)
{
char *c = btree_string;
BTree *STACK[1024], *root, *node, *p;
int flag = 0, top = -1;
while (*c)
{
switch (*c)
{
case '(':
flag = 1; // left tree
STACK[++top] = p;
break;
case ')':
--top;
break;
case ',':
flag = 2; // right tree
break;
case '@':
return root;
break;
default:
p = (BTree *)malloc(sizeof(BTree));
p->data = *c;
p->ltree = NULL;
p->rtree = NULL;
if (flag == 0)
root = p;
else if (flag == 1)
STACK[top]->ltree = p;
else if (flag == 2)
STACK[top]->rtree = p;
}
c++;
}
return root;
}
/**
* 计算叶结点的数目
*/
int countLeaf(BTree *bt)
{
if (bt == NULL)
return 0;
if (bt->ltree == NULL && bt->rtree == NULL)
return 1;
return (countLeaf(bt->rtree) + countLeaf(bt->ltree));
}
/**
* 计算树的深度
*/
int treeDepth(BTree *bt)
{
int leftdep, rightdep;
if (bt == NULL)
return 0;
leftdep = treeDepth(bt->ltree);
rightdep = treeDepth(bt->rtree);
return leftdep > rightdep ? (leftdep + 1) : (rightdep + 1);
}
/**
* 前序遍历:
* 1. 访问根节点
* 2. 以前序遍历的方式访问根节点的左子树
* 3. 以前序遍历的方式访问根节点的右子树
*/
void preOrderPrint(BTree *bt)
{
if (bt == NULL)
return;
printf("%c\t", bt->data);
preOrderPrint(bt->ltree);
preOrderPrint(bt->rtree);
}
/**
* 中序遍历:
* 1. 以中序遍历的方式访问根节点的左子树
* 2. 访问根节点
* 3. 以中序遍历的方式访问根节点的右子树
*/
void inOrderPrint(BTree *bt)
{
if(bt == NULL)
return;
inOrderPrint(bt->ltree);
printf("%c\t", bt->data);
inOrderPrint(bt->rtree);
}
/**
* 后序遍历
* 1. 以后序遍历的方式访问根结点的左子树
* 2. 以后学遍历的方式访问根基结点的右子树
* 3. 访问根节点
*/
void postOrderPrint(BTree *bt)
{
if(bt == NULL)
return;
postOrderPrint(bt->ltree);
postOrderPrint(bt->rtree);
printf("%c\t", bt->data);
}
/**
* 按层次遍历
* 使用队列遍历树
*/
void layerOrderPrint(BTree *bt)
{
BTree *QUEUE[50], *p;
int front, rear;
if(bt == NULL)
return;
QUEUE[0] = bt;
front = -1;
rear = 0;
while(front < rear)
{
p = QUEUE[++front];
printf("%c\t", p->data);
if(p->ltree != NULL)
QUEUE[++rear] = p->ltree;
if(p->rtree != NULL)
QUEUE[++rear] = p->rtree;
}
}
int main()
{
char *p = "A(B(D,E(G)),C(F(,H)))@";
BTree *bt = createBinaryTreeFromString(p);
preOrderPrint(bt);
printf("\n");
inOrderPrint(bt);
printf("\n");
postOrderPrint(bt);
printf("\n");
layerOrderPrint(bt);
printf("\nleaf number: %d\n", countLeaf(bt));
printf("tree depth: %d\n", treeDepth(bt));
return 1;
}2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
二叉排序树
二叉排序树(Binary sort tree) 是一棵二叉树,若根结点的左子树不为空,则左子树中所有的结点的值都小于根节点的值;若右子树不为空,则右子树的所有结点的值均大于或等于根节点的值。
C 示例:
/**
* 二叉排序树
*/
#include <stdio.h>
#include <stdlib.h>
typedef struct BSTree
{
int data;
struct BSTree *ltree, *rtree;
} BSTree;
/**
* 插入结点
*/
void insert(BSTree **ptr, int item)
{
BSTree *bst;
if (*ptr == NULL){
bst = (BSTree *)malloc(sizeof(BSTree));
bst->data = item;
bst->ltree = NULL;
bst->rtree = NULL;
*ptr = bst;
}
else {
bst = *ptr;
if (bst->data > item)
insert(&bst->ltree, item);
else
insert(&bst->rtree, item);
}
}
BSTree *search(BSTree *bst, int item)
{
BSTree *p = bst;
while(p != NULL){
if(p->data == item)
return p;
else if(p->data > item)
p = p->ltree;
else
p = p->rtree;
}
return NULL;
}
/**
* 中序遍历
*/
void inOrderPrint(BSTree *bst)
{
if (bst == NULL)
return;
inOrderPrint(bst->ltree);
printf("%d\t", bst->data);
inOrderPrint(bst->rtree);
}
int main(int argc, char const *argv[])
{
BSTree *bst;
insert(&bst, 2);
insert(&bst, 5);
insert(&bst, 5);
insert(&bst, 10);
insert(&bst, 12);
insert(&bst, 17);
insert(&bst, 19);
insert(&bst, 20);
inOrderPrint(bst);
printf("\n");
inOrderPrint(search(bst, 10));
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
查找的长度
在二叉排序树的中查找数据信息与给定值相匹配的结点的过程正好走了一条从根结点到该结点的路径,与给定值所进行的比较次数等于该结点所在层次数。对于二叉排序树的查找算法的优劣性通常采用 平均查找长度(Average Search Length, ASL) 的概念来衡量。ASL确定一个元素在树中的位置所需要进行的比较次数的期望值。
从二叉树根结点到某结点所经过的分支数目定义为该结点的路径长度。二叉树内所有结点的路径长度之和为该二叉树的内路径长度(Internel Path Length, IPL)。
为了分析查找失败时的查找长度,在二叉树中出现空子树时,增加新的空叶结点来代表这些空子树,从而得到一棵扩充后的二叉树,称之为外部结点,树中原有的结点称为内部结点。内外部结点的路径长度和称为外路径长度(External Path Length, EPL)。
由归纳法可以证明 EPL = IPL + 2n。设对每个结点(包括外结点)进行查找的概率相等,则平均查找长度为:
ASL = (2IPL + 3n) / (2n + 1)
- 内路径长度最小时二叉排序树具有最小的平均查找长度,此时称之为最佳二叉排序树。 O(log2n)量级。
- 最坏的情况下,二叉树退化成一棵单枝的二叉树,其平均长度为(n+1)/2,是O(n)量级,与顺序查找相同。
平衡二叉树
平衡二叉树(balanced binary tree或height-balanced tree)又称AVL树(得名于它的发明者G.M. Adelson-Velsky 和E.M. Landis)。它是具有下列性质的二叉树:二叉树中每个结点的左、右子树的深度之差的绝对值不超过1。把二叉树中的每个结点的左子树深度与右子树深度之差定义为该结点的平衡因子(-1, 0或者1)。
- LL型调整 对由于在结点A的左(L)孩子(用B表示)的左(L)子树上插入结点,使得点A的平衡因子由1变成2而引起的不平衡所进行的调整操作。
- RR型调整 对由于在结点A的右(R)孩子(用B表示)的右(R)子树上插入结点,使得点A的平衡因子由-1变成-2而引起的不平衡所进行的调整操作。
- LR型调整 对由于在结点A的左(L)孩子(用B表示)的右(R)子树上插入结点,使得点A的平衡因子由1变成2而引起的不平衡所进行的调整操作。
- RL型调整 对由于在结点A的右(R)孩子(用B表示)的左(L)子树上插入结点,使得点A的平衡因子由-1变成-2而引起的不平衡所进行的调整操作。
哈夫曼树(Huffman)
若设二叉树有m个叶结点,每个叶结点分别赋予一个权值,则二叉树的带权路径长度为
WPL = w1l1 + w2l2 + ... + wmlm
给定一组权值,构造出的具有最小带权路径长度的二叉树称为哈夫曼树, 又称为最优叉树。构造最优WPL的叉树的算法是哈夫曼给出的,称为哈夫曼算法。
- 将w1、w2、…,wn看成是有n 棵树的森林(每棵树仅有一个结点);
- 在森林中选出根结点的权值最小的两棵树进行合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和;
- 从森林中删除选取的两棵树,并将新树加入森林;
- 重复2、3步,直到森林中只剩一棵树为止,该树即为所求得的哈夫曼树。 以{2,4,5,7}为例,来构造一棵哈夫曼树。
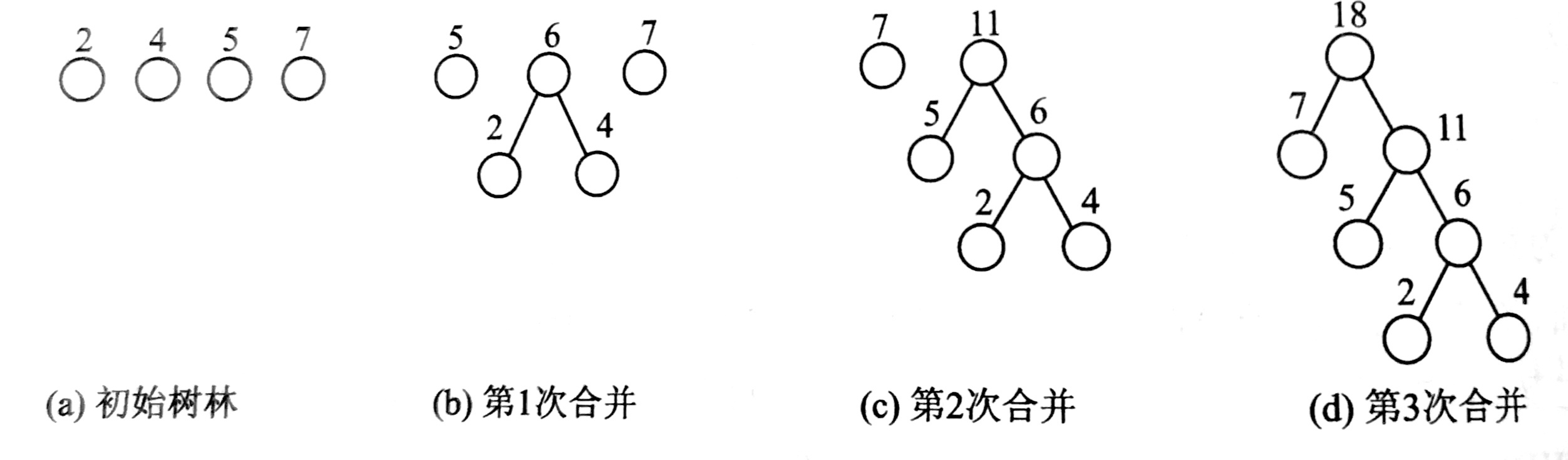
哈夫曼编码
哈法曼编码是一种无损的数据压缩算法。算法的基本思想是给输入的字符分配变长的编码,编码的长度取决于相应字符出现的频率。频率越高的字符分配越短的编码,频率越低的字符则分配越长的编码。
分配给输入字符的变长编码称为字首码(Prefix Codes),一个字符对应的编码(位序列,bit sequences)不是其他任何一个字符的编码的前缀。这能确保哈夫曼编码解码生成的字节流时不会产生歧义。举个例子,假设四个字母对应的a,b,c,d和相应的变长编码00, 01, 0和1。这种编码会导致歧义,因为c对应的编码是a和b对应编码的前缀。假设有编码的字节流是0001,那么解码后的输出可能是”cccd“或者”ccb“或者”acd“或者”ab“。
C 示例: 实现步骤:
- 为每个不同的字符创建一个树结点,然后建立一个最小堆(最小堆用来排序,最小堆中的不同结点通过频率的大小来比较。最开始,根节点的频率最低);
- 从最小堆中取出频率最低的两个结点;
- 对这两个结点求和并创建一个新的内部结点。第一个取出的结点左右它的左孩子,另外一个作为右孩子。将这个新的内部结点加入到最小堆中;
- 重复2,3知道这个堆只包含一个结点。剩下的最后一个结点是根节点。
举例说明:
1. 建立最小堆后
character Frequency
a 5
b 9
c 12
d 13
e 16
f 45
2. 从最小堆中取出最小的两个结点。增加一个新的内部结点,频率为 5 + 9 = 14
character Frequency
c 12
d 13
Internal Node 14
e 16
f 45
3. 重复2
character Frequency
Internal Node 14
e 16
Internal Node 25
f 45
4. 重复2
character Frequency
Internal Node 25
Internal Node 30
f 45
5. 重复2
character Frequency
f 45
Internal Node 55
6. 重复2
character Frequency
Internal Node 100
7. 最终得到的树如下图,打印编码
character code-word
f 0
c 100
d 101
a 1100
b 1101
e 111
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
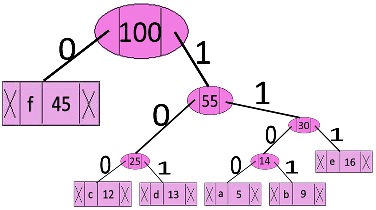
/**
* 哈弗曼编码实现
* 给点一个字符数组和它们相应的频率,输出所有的给点字符的哈夫曼编码。
* 如果有两个元素的频率相同,则第一个出现的字符占据左子树,后者占据右子树
*
* [限制]
* 1 <= 频率 <= 100,1 <= 字符串长度 <= 26
*
* [输入]
* abcdef
* 5 9 12 13 16 45
* [编码]
* f: 0
* c: 100
* d: 101
* a: 1100
* b: 1101
* e: 111
* [输出]
* 0 100 101 1100 1101 111
*/
#include <stdio.h>
#include <stdlib.h>
#define MAX_TREE_HT 100
// 一个哈夫曼树节点,最小堆结点
typedef struct MinHeapNode {
char data;
unsigned freq;
struct MinHeapNode *left, *right;
} MinHeapNode;
// 最小堆
typedef struct MinHeap {
unsigned size;
unsigned capacity;
MinHeapNode **array;
} MinHeap;
// 新分配一个最小堆结点
MinHeapNode *newNode(char data, unsigned freq)
{
MinHeapNode *tmp = (MinHeapNode *)malloc(sizeof(MinHeapNode));
tmp->data = data;
tmp->freq = freq;
tmp->left = tmp->right = NULL;
return tmp;
}
// 初始化最小堆
MinHeap *createMinHeap(unsigned capacity)
{
MinHeap * mp = (MinHeap *) malloc(sizeof(MinHeap));
mp->capacity = capacity;
mp->size = 0;
mp->array = (MinHeapNode **)malloc(mp->capacity * sizeof(MinHeapNode));
return mp;
}
// 交换最小堆的两个结点
void swapMinHeapNode(MinHeapNode **a, MinHeapNode **b)
{
MinHeapNode *t = *a;
*a = *b;
*b = t;
}
// Heapify
void minHeapify(MinHeap *mp, int idx)
{
int smallest = idx;
int left = 2 * idx + 1;
int right = 2 *idx + 2;
if(left < mp->size && mp->array[left]->freq < mp->array[smallest]->freq)
smallest = left;
if(right < mp->size && mp->array[right]->freq < mp->array[smallest]->freq)
smallest = right;
if(smallest != idx){
swapMinHeapNode(&mp->array[smallest], &mp->array[idx]);
minHeapify(mp, smallest);
}
}
// 最小堆的大小是否为 1
int isSizeOne(MinHeap *mp)
{
return (mp->size == 1);
}
// 是否为叶结点
int isLeaf(MinHeapNode *mhn)
{
return !(mhn->left) && !(mhn->right);
}
// 取出频率最小的结点
MinHeapNode *extractMin(MinHeap *mp)
{
MinHeapNode *tmp = mp->array[0];
mp->array[0] = mp->array[--mp->size];
minHeapify(mp, 0);
return tmp;
}
// 插入一个结点
void insertMinHeap(MinHeap *mp, MinHeapNode *mhn)
{
int i = mp->size;
++mp->size;
while(i && mhn->freq < mp->array[(i - 1) / 2]->freq)
{
mp->array[i] = mp->array[(i - 1) / 2];
i = (i - 1) / 2;
}
mp->array[i] = mhn;
}
// 堆排序
void buildMinHeap(MinHeap *mp)
{
int n = mp->size - 1;
int i;
for(i = (n - 1)/2; i >= 0; i--)
minHeapify(mp, i);
}
// 从数组创建最小堆
MinHeap *createAndBuildMinHeap(char data[], int freq[], int size)
{
MinHeap *mp = createMinHeap(size);
for(int i=0; i < size; i++)
mp->array[i] = newNode(data[i], freq[i]);
mp->size = size;
buildMinHeap(mp);
return mp;
}
MinHeapNode *buildHuffmanTree(char data[], int freq[], int size)
{
MinHeapNode *left, *right, *top;
MinHeap *mp = createAndBuildMinHeap(data, freq, size);
while(!isSizeOne(mp)){
left = extractMin(mp);
right = extractMin(mp);
top = newNode('$', left->freq + right->freq);
top->left = left;
top->right = right;
insertMinHeap(mp, top);
}
// 最后剩余的一个结点是根节点,树结构已经完整
return extractMin(mp);
}
void printArr(int arr[], int n)
{
int i;
for(i = 0; i < n; i++)
printf("%d", arr[i]);
printf("\n");
}
void printCodes(MinHeapNode *root, int arr[], int top)
{
if(root->left){
arr[top] = 0;
printCodes(root->left, arr, top + 1);
}
if(root->right){
arr[top] = 1;
printCodes(root->right, arr, top + 1);
}
if(isLeaf(root)){
printf("%c: ", root->data);
printArr(arr, top);
}
}
void HuffmanCodes(char data[], int freq[], int size)
{
MinHeapNode *root = buildHuffmanTree(data, freq, size);
int arr[MAX_TREE_HT], top = 0;
printCodes(root, arr, top);
}
int main()
{
char arr[] = {'a', 'b', 'c', 'd', 'e', 'f'};
int freq[] = {5, 9, 12, 13, 16, 45};
int size = sizeof(arr) / sizeof(arr[0]);
HuffmanCodes(arr, freq, size);
return 0;
}2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
图
图(graph)是由顶点的非空有限集合V(由n>0个顶点组成)与边的集合E(顶点之间的关系)构成的。一般称图中的一个数据元素为一个 顶点(vertex),两个顶点之间的关系称为边(edge) 或弧(arc)。若图G中的每天边都是没有方向的则称之为无向图,反之为有向图。与边有关的数据信息称为权,每条边上都带有权的图称为网络,简称网。
顶点的度是指依附于某顶点的边数。有向图顶点的入度是指以顶点为终点的弧的数据。顶点的出度是指以顶点为始点的弧的数目。出度和入度之和就是顶点的度。
具有n个顶点的无向图最多有n(n-1)/2条边,称这样的图为完全图。具有n个顶点的有向图最多有n(n-1)条边,这样的有向图称为有向完全图。若一个图接近于完全图,称为稠密图,反之称为稀疏图。
如果无向图中任意两个顶点之间都是连通的,则称该无向图为连通图。无向图中的极大连通子图称为该图的连通分量。若有向图中的任意两个顶点都是连通的(v1到v2和v2到v1都是连通的),则称该有向图为强连通图,有向图中的极大强连通子图称为该有向图的强连通分量。
若图为包含n个顶点的连通图,所谓该图的生成树是该图的一个包含全部n个顶点的极小连通子图,并且该子图一定包含且仅仅包含该图的n-1条边。
一个有向图的生成森林由若干棵有向树组成,包含图中的全部顶点,但只有足以构成若干棵不相交的有向树的弧。
图的存储方法
邻接矩阵存储方法
定义一个二维数组A[0..n-1][0..n-1],该二维数组通常被称为邻接矩阵,元素A[i][j]存放顶点i到顶点j之间的关系信息。
邻接表存储方法
邻接矩阵存储方法不适合稀疏图,而实际经常遇到的大多数问题又不是稠密图,一个较好的解决办法就是邻接表存储方法。
在这种存储方法里,对于每一个顶点都建立一个线性链表,链表的前面设置一个头结点,每个顶点结点由两个域组成,顶点域(vertex)用来存放某个定点的数据信息,指针域(link)用来存放该顶点的第一个边所对应的链接点的地址。为了方便呢随机访问任意一个顶点的链表,所有的表头都会存储在一个数组中。
C 示例:
/**
* C 程序示例用来实现【邻接表存储方法】来表示无向图
*/
#include <stdio.h>
#include <stdlib.h>
// 邻接列表结点
typedef struct AdjListNode
{
int dest;
int weight;
struct AdjListNode *next;
} AdjListNode;
// 邻接列表表头
typedef struct AdjList
{
char *vertex;
AdjListNode *head;
} AdjList;
typedef struct Graph
{
int size;
struct AdjList *array;
} Graph;
AdjListNode *newAdjListNode(int dest, int weight)
{
AdjListNode *aln = (AdjListNode *)malloc(sizeof(AdjListNode));
aln->dest = dest;
aln->weight = weight;
aln->next = NULL;
return aln;
}
Graph *createGraph(int size)
{
int i;
Graph *g = (Graph *)malloc(sizeof(Graph));
g->size = size;
g->array = (AdjList *)malloc(size * sizeof(AdjList));
for(i = 0; i < size; i++){
g->array[i].vertex = NULL;
g->array[i].head = NULL;
}
return g;
}
/**
* 添加边
* !!!没有考虑边已经添加过了的情况!!!
*/
void addEdge(Graph *g, int src, int dest, int weight)
{
AdjListNode *new = newAdjListNode(dest, weight);
new->next = g->array[src].head;
g->array[src].head = new;
// 无向图
new = newAdjListNode(src, weight);
new->next = g->array[dest].head;
g->array[dest].head = new;
}
void setVertex(Graph *g, int idx, char *vertex)
{
g->array[idx].vertex = vertex;
}
void printGraph(Graph *g)
{
int size;
for(size = 0; size < g->size; size++)
{
AdjListNode *node = g->array[size].head;
printf("%s->", g->array[size].vertex);
while(node){
printf("%s(%d)->", g->array[node->dest].vertex, node->weight);
node = node->next;
}
printf("\n");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
图的遍历
遍历图的方式通常有两种,分别是深度优先搜索和广度优先搜索。以下图为例,分别实现图的两种遍历方式。
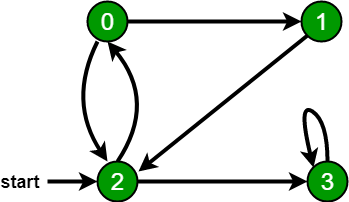
#include <stdio.h>
#include <stdlib.h>
typedef struct AdjListNode
{
int dest;
struct AdjListNode *next;
} AdjListNode;
typedef struct AdjList
{
AdjListNode *head;
} AdjList;
typedef struct Graph
{
int size;
struct AdjList *array;
} Graph;
AdjListNode *newAdjListNode(int dest)
{
AdjListNode *aln = (AdjListNode *)malloc(sizeof(AdjListNode));
aln->dest = dest;
aln->next = NULL;
return aln;
}
Graph *createGraph(int size)
{
int i;
Graph *g = (Graph *)malloc(sizeof(Graph));
g->size = size;
g->array = (AdjList *)malloc(size * sizeof(AdjList));
for (i = 0; i < size; i++)
{
g->array[i].head = NULL;
}
return g;
}
void addEdge(Graph *g, int src, int dest)
{
AdjListNode *new = newAdjListNode(dest);
AdjListNode *tail = g->array[src].head;
if(!tail){
g->array[src].head = new;
return;
}
while(tail->next)
tail = tail->next;
tail->next = new;
}
void arraySetToZero(int arr[], int size)
{
for (int i = 0; i < size; i++)
arr[i] = 0;
}
// 深度优先搜索
void dfs(Graph *g, int idx, int visited[])
{
AdjListNode *node = g->array[idx].head;
printf("%d", idx);
visited[idx] = 1;
while (node)
{
if(!visited[node->dest])
dfs(g, node->dest, visited);
node = node->next;
}
}
// 广度优先
void bfs(Graph *g, int idx, int visited[])
{
if(!visited[idx]){
printf("%d", idx);
visited[idx] = 1;
}
int i, j, *queue;
queue = (int *)malloc(sizeof(int) * g->size);
for(i=0;i<g->size;i++)
queue[i] = 0;
i = 0;
AdjListNode *node = g->array[idx].head;
while(node){
if(!visited[node->dest]){
queue[i++] = node->dest;
printf("%d", node->dest);
visited[node->dest] = 1;
}
node = node->next;
}
}
int main()
{
Graph *g = createGraph(4);
addEdge(g, 0, 1);
addEdge(g, 0, 2);
addEdge(g, 1, 2);
addEdge(g, 2, 0);
addEdge(g, 2, 3);
addEdge(g, 3, 3);
int i, visited[4];
arraySetToZero(visited, 4);
printf("dfs: ");
dfs(g, 2, visited);
for(i = 0; i < 4; i++){
if(!visited[i])
dfs(g, i, visited);
}
printf("\nbfs: ");
arraySetToZero(visited, 4);
bfs(g, 2, visited);
for (i = 0; i < 4; i++)
{
if (!visited[i])
bfs(g, i, visited);
}
printf("\n");
}2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
最小生成树
什么是最小生成树?
对于一个连通的无向图来说,它的一个连通树就是该图的子图,这个子图连接了所有的顶点。一个图可以有很多不同的连通树。最小生成树( Minimum Spanning Tree, MST) 是带权无向连通图的一棵权和最小(或者其他所有连通树相等)的连通树。连通树的权值就是该连通树所有边的权值之和。
最小生成树有多少个边呢?
假设图由V个顶点,那么最小连通树由(V-1)个边。
构造最小生成树的基本原则是:
- 只能使用该连通图的边来构造最小生成树;
- 只能使用并且仅能使用n-1条边来连接该连通图的n个顶点;
- 不能使用产生回路的边。
构造最小生成树的方法有很多种,比较典型的方法是普利姆 算法和可如斯卡尔 算法。
可如斯卡尔 Kruskal’s Minimum Spanning Tree Algorithm
通过可如斯卡尔算法查找MST的步骤:
- 按权值大小升序排列所有的边;
- 选择最小的边。检查它是否和现有的树形成回路,如果没有则保留该边,所有弃用;
- 重复2直到生成树中有V-1条边。
举一个例子:
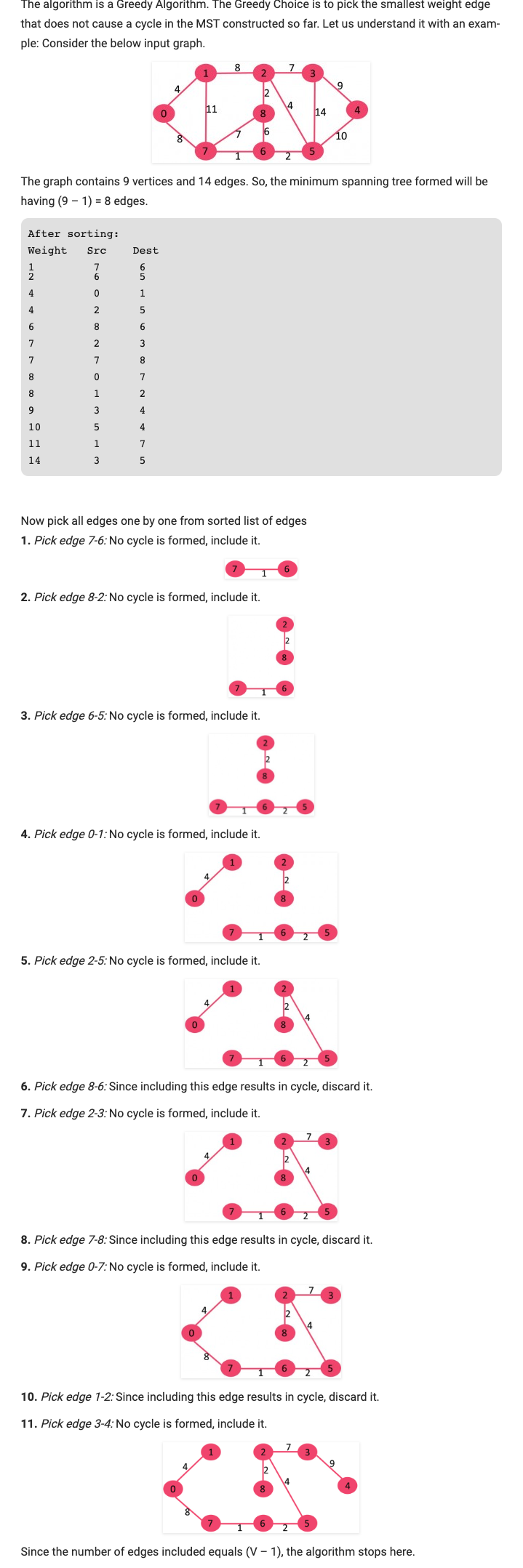
/**
* Kruskal 算法的C实现,用来找到一个无向连通带权图的最小生成树
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct Edge
{
int src, dest, weight;
};
struct Graph
{
// V 顶点数,E是边数
int V, E;
// 使用edge数组来表示图。因为是无向图,所以src到dest的边和dest到src的边是同一条。
// 在这里,我们只记一次
struct Edge* edge;
};
struct Graph *createGraph(int V, int E)
{
struct Graph *graph = (struct Graph *)malloc(sizeof(struct Graph));
graph->V = V;
graph->E = E;
graph->edge = (struct Edge *)malloc(sizeof(struct Edge) * E);
return graph;
}
void printGraph(struct Graph *graph)
{
for (int e = 0; e < graph->E; e++)
printf("%d -- %d: %d\n", graph->edge[e].src, graph->edge[e].dest, graph->edge[e].weight);
}
struct subset
{
int parent;
int rank;
};
int myComp(const void*a, const void *b)
{
struct Edge *a1 = (struct Edge *)a;
struct Edge *b1 = (struct Edge *)b;
return a1->weight - b1->weight;
}
int find(struct subset *subsets, int i)
{
if(subsets[i].parent != i)
subsets[i].parent = find(subsets, subsets[i].parent);
return subsets[i].parent;
}
void Union(struct subset *subsets, int x, int y)
{
int xroot = find(subsets, x);
int yroot = find(subsets, y);
// 将rank小的树连接到root rank高的树后面
if(subsets[xroot].rank < subsets[yroot].rank)
subsets[xroot].parent = yroot;
else if(subsets[xroot].rank > subsets[yroot].rank)
subsets[yroot].parent = xroot;
else {
subsets[yroot].parent = xroot;
subsets[xroot].rank++;
}
}
void KruskalMST(struct Graph *graph)
{
int V = graph->V;
struct Edge result[V];
int e = 0; // result的索引
int i = 0; // sorted edges的索引
// 第一步:按权值升序排列所有的边。
qsort(graph->edge, graph->E, sizeof(graph->edge[0]), myComp);
// 初始化subsets
struct subset *subsets = (struct subset *)malloc(sizeof(struct subset) * V);
// subsets的索引号和边的编号一致
for(int v = 0; v < V; v++){
subsets[v].parent = v;
subsets[v].rank = 0;
}
// 要选的边的数目等于 V-1
while(e < V - 1){
// 第二步:选择权值最小的边
struct Edge next_edge = graph->edge[i++];
int x = find(subsets, next_edge.src);
int y = find(subsets, next_edge.dest);
// 如果这个边不会形成回路,则包含,否则不用该边
if(x != y){
result[e++] = next_edge;
Union(subsets, x, y);
}
}
printf("Following are the edges in the constructed MST\n");
for (i = 0; i < e; ++i)
printf("%d -- %d == %d\n", result[i].src, result[i].dest,
result[i].weight);
}
void freeGraph(struct Graph *graph)
{
free(graph->edge);
free(graph);
}
int main()
{
/* 创建如下带权图
10
0--------1
| \ |
6| 5\ |15
| \ |
2--------3
4 */
int V = 4;
int E = 5;
struct Graph *graph = createGraph(V, E);
graph->edge[0].src = 0; graph->edge[0].dest = 1; graph->edge[0].weight = 10; // 0-1边
graph->edge[1].src = 0; graph->edge[1].dest = 2; graph->edge[1].weight = 6; // 0-2边
graph->edge[2].src = 0; graph->edge[2].dest = 3; graph->edge[2].weight = 5; // 0-3边
graph->edge[3].src = 1; graph->edge[3].dest = 3; graph->edge[3].weight = 15; // 1-3边
graph->edge[4].src = 2; graph->edge[4].dest = 3; graph->edge[4].weight = 4; // 2-3边
KruskalMST(graph);
freeGraph(graph);
return 0;
}2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
普利姆算法 Prim’s Minimum Spanning Tree (MST)
和Kruskal's algorithm 一样,Prim's algorithm 也是一种 贪婪算法。该算法的核心是维护两个顶点的集合,第一个集合包含MST,另外一个包含没有加入MST的顶点。每一步,都考虑连接这两个集合的所有边,选择权值最小的。选择边之后,将另一个顶点移动到MST集合中。
在图中,有两个顶点集合通过一组边连接,这种思想称为切入图理论(cut in graph theory)。在普利姆算法中,我们需要一个切点(两个集合间,一个包含已经加入MST顶点的集合,一个包含剩余顶点的集合),从切点选择权值最小的边,把顶点加入到MST集合中。
普利姆算法为何可行? 普利姆算法的本质很简单,一个生成树意味着所有的顶点都必须是连通的。所以,两个不相交的顶点集合必须连接起来以组成生成树,并且一定要通过最小的权值的边来连接。
算法
- 创建mstSet集合用来记录包含在MST中的顶点
- 为图中的每一个顶点分配一个key值。所有的key值初始化为无穷大。第一个被选的定点的的key值赋值为0
- 当mstSet不包含所有的顶点时:
- 选择一个不在mstSet集合中、有最小的key值的顶点u
- 将u加入到mstSet中
- 更新所有和u相连的顶点的key值。迭代的更新所有相连的顶点的key值。对于每个相连的顶点v,如果如果边u-v的权值小于之前的v的的key值,将key值更新为u-v边的权值。
Key值只用于那些没有加入到MST中的顶点,这些顶点的Key与它们和MST顶点相连的权值最小的边相关。
以下图为例,起始时mstSet是空的,所有的顶点的Key赋值为 {0, INF, INF, INF, INF, INF, INF, INF} ,INF表示无限大。
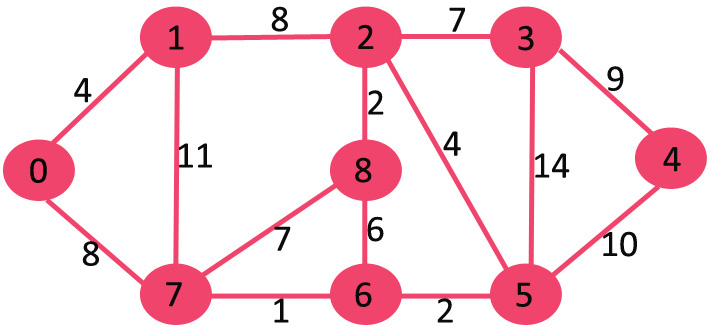
选择key最小的的顶点。顶点0被选择,加入mstSet,mstSet成了{0}。加入mstSet后开始更新邻接顶点的key值,顶点0的连接顶点是1和7。更新1和7的key值为4和8。接下来选择key最小的邻接顶点,自然是顶点1,加入mstSet。更新邻接顶点的key。忽略key值为INF,图如下所示。

依此类推。
// A C / C++ program for Prim's Minimum
// Spanning Tree (MST) algorithm. The program is
// for adjacency matrix representation of the graph
#include <stdio.h>
#include <limits.h>
#include <stdbool.h>
// Number of vertices in the graph
#define V 5
// A utility function to find the vertex with
// minimum key value, from the set of vertices
// not yet included in MST
int minKey(int key[], bool mstSet[])
{
// Initialize min value
int min = INT_MAX, min_index;
for (int v = 0; v < V; v++)
if (mstSet[v] == false && key[v] < min)
min = key[v], min_index = v;
return min_index;
}
// A utility function to print the
// constructed MST stored in parent[]
int printMST(int parent[], int n, int graph[V][V])
{
printf("Edge \tWeight\n");
for (int i = 1; i < V; i++)
printf("%d - %d \t%d \n", parent[i], i, graph[i][parent[i]]);
}
// Function to construct and print MST for
// a graph represented using adjacency
// matrix representation
void primMST(int graph[V][V])
{
// Array to store constructed MST
int parent[V];
// Key values used to pick minimum weight edge in cut
int key[V];
// To represent set of vertices not yet included in MST
bool mstSet[V];
// Initialize all keys as INFINITE
for (int i = 0; i < V; i++)
key[i] = INT_MAX, mstSet[i] = false;
// Always include first 1st vertex in MST.
// Make key 0 so that this vertex is picked as first vertex.
key[0] = 0;
parent[0] = -1; // First node is always root of MST
// The MST will have V vertices
for (int count = 0; count < V - 1; count++)
{
// Pick the minimum key vertex from the
// set of vertices not yet included in MST
int u = minKey(key, mstSet);
// Add the picked vertex to the MST Set
mstSet[u] = true;
// Update key value and parent index of
// the adjacent vertices of the picked vertex.
// Consider only those vertices which are not
// yet included in MST
for (int v = 0; v < V; v++)
// graph[u][v] is non zero only for adjacent vertices of m
// mstSet[v] is false for vertices not yet included in MST
// Update the key only if graph[u][v] is smaller than key[v]
if (graph[u][v] && mstSet[v] == false && graph[u][v] < key[v])
parent[v] = u, key[v] = graph[u][v];
}
// print the constructed MST
printMST(parent, V, graph);
}
// driver program to test above function
int main()
{
/* Let us create the following graph
2 3
(0)--(1)--(2)
| / \ |
6| 8/ \5 |7
| / \ |
(3)-------(4)
9 */
int graph[V][V] = {{0, 2, 0, 6, 0},
{2, 0, 3, 8, 5},
{0, 3, 0, 0, 7},
{6, 8, 0, 0, 9},
{0, 5, 7, 9, 0}};
// Print the solution
primMST(graph);
return 0;
}2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
最短路径
AOV网与拓扑排序
文件及查找
B-Tree
B-树是一个自平衡搜索树。和大多数的其他自平衡搜索树(如AVL和红黑树)一样,假设所有的数据都保存在主存中。为了理解B-树的使用,我们必须知道大量的数据是不能同时存在内存中的。当键的数目很高时,就需要从磁盘中以块的形式读取数据。和从主存中获取数据相比,从磁盘中读取数据要消耗很多的时间。B-树的核心思想就是减少磁盘I/O的次数。大多数树操作(查询,插入,删除,最大,最小等)需O(h)的磁盘读取次数(h是树的高度)。通过在B-树节点中记录尽可能多的键来保持树的低高度。通常,一个B-树节点的大小等于磁盘块的大小。尽管和其他的AVL树,红黑树相比,B-树的h较小,但是磁盘操作的次数也显著的降低了。
B-树的特性
- 所有的叶结点都在相同的层。
- 最小度 't' 决定了B-树节点的大小,t的大小取决于磁盘块的大小。
- 每个结点(除了根节点外)至少包含t-1个键,根可以最少包含1个键。
- 所有的结点(包括根节点)最多可包含2t-1个键。
- 结点的子结点的数目等于该结点的键数目+1。
- 结点中的所有键按升序排列。介于k1和k2之间的子结点包括的所有键的大小都介于k1和k2之间。
- B-树从根节点扩增和缩减和二叉搜索树不同。二叉搜索树向下扩增同时也向下缩减。
- 和其他平衡二叉搜索树一样,搜索,插入和删除的时间复杂度的都是O(Logn)。
// C++ 实现搜索和bianli
#include <iostream>
using namespace std;
// BTree node
class BTreeNode
{
int *keys; // 键数组
int t; // 最小的度,定义键值的范围
BTreeNode **C; // 子节点指针
int n; // 当前键的数目
bool leaf; // 是否是叶结点
public:
BTreeNode(int _t, bool _leaf); // 构造器
void traverse(); // 从根节点开始遍历所有的结点
BTreeNode *search(int k); // 查找k是否存在
friend class BTree; // 声明友元类
};
class BTree
{
BTreeNode *root; // 根节点指针
int t; // 最小度
public:
// 构造器
BTree(int _t){
root = NULL;
t = _t;
}
// 遍历树的函数
void traverse()
{
if(root != NULL) root->traverse();
}
// 查找
BTreeNode *search(int k){
return (root == NULL) ? NULL : root->search(k);
}
};
BTreeNode::BTreeNode(int _t, bool _leaf)
{
t = _t;
leaf = _leaf;
keys = new int[2*t -1];
C = new BTreeNode *[2*t];
n = 0;
}
void BTreeNode::traverse()
{
int i;
for(i = 0; i < n; i ++)
{
if(leaf == false)
C[i]->traverse();
cout << " " << keys[i];
}
if(leaf == false)
C[i]->traverse();
}
BTreeNode *BTreeNode::search(int k)
{
int i = 0;
while(i < n && k > keys[i])
i++;
// 假如找到键值为k的结点,返回这个结点
if(keys[i] == k)
return this;
// 键值为k的结点没有找到,当前结点是叶结点
if(leaf == true)
return NULL;
return C[i]->search;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
插入和删除可以参考:B-Tree | Set 2 (Insert), B-Tree | Set 3 (Delete)。
散列文件
散列函数的几种常见构造方法
- 直接定址法: 直接取关键字的某个线性函数作为散列函数。
- 数字分析法: 当关键字的位数大于散列地址码的位数时,对关键字值得各位数字进行分析,从中取出与散列地址位数相同的位。该方法适用于所有关键字可能出现的值已知的情况下。
- 平方取中法: 先计算关键字值的平方,然后有目的的选取中间的若干位作为散列地址。
- 叠加法: 把关键字分割成位数相同的几个部分,然后把这几个部分的叠加和作为散列地址。
- 基数转换法: 设关键字原来是十进制数,认为当着q进制数,再转换成十进制数后作为散列地址。
- 除留余数法: 取模法。
处理冲突的方法
- 开放定址法: 将散列表中的“空”地址向处理冲突开放,当散列表未满时,处理冲突需要的“下一个”空位置在该散列表中解决。
- 再散列法: 发生冲突时用不同的散列函数再求得新的散列地址,直到不发生冲突时为止。
- 链地址法: 把具有相同散列地址的元素用一个线性链表连接在一起。
- 建立一个公共溢出区: 假若散列函数的值域为[0, m-1],则设置一个向量hashTABLE[0..m-1],称之为基本表,每个分量存放一个记录,另外再设置一个向量overTable[0..v],称为溢出表。所有的关键字和基本表中的关键字为同义词的记录,不管它们通过散列函数计算得到的散列地址什么,一旦发生冲突,都将填入溢出表。