共享内存哈希表
最近在学习共享内存区的知识,通过共享内存区的方式实现进程间通讯的效率比网络通讯会高很多,于是想到是不是可以通过共享内存的方式在多个进程间共享缓存呢?比如,可以在运行多个php-fpm works的主机上共享配置或者数据,进而大大减少文件IO和内存占用了,一台机器获取可以运行更多的works了。
用共享内存区来作为键值对数据的缓存,主要是解决读写、查找和动态扩容缩容的问题了。对于读写、查找删除等问题,我们可以简单的通过哈希表来解决。而对于动态调整共享内存区的话就有些麻烦了。为了简化问题,设想更新共享内存区的进程(就称之为server进程吧,用于定期刷新缓存区,读取配置或者数据文件来更新缓存区,并且根据数据大小动态调整共享内存区的大小)只有一个,其好处在于不用考虑写锁的问题。server进程如何动态调整共享内存的大小而不影响其他进程读取数据呢?思前想后觉得开辟一块新的共享内存区来写入数据,然后告诉其他进程,来读取这块新的缓存区吧,旧的已经过时了!
可是问题又来了,如何及时通知其他进程共享内存区变了呢?通知它们必须得及时且高效啊,更重要的是不能影响效率和性能。也许你们也能想到,那就再来一块共享内存区吧,专门用来记录当前最近的共享内存区是哪个。其他进程(暂时称之为client进程吧,虽然感觉不太合理)每次先读取”版本“共享区内存的数据,获悉当前最近版本的共享内存区的名字(如ftok的返回值),根据名字映射相应的缓存共享内存区,进而读取最近的缓存。
这样问题就有些眉目了,先简单的用PHP来实现一下吧!于是新建了一个项目ShareCache: Cache key-values in share memory for multiple processes to read without read lock,用来缓存配置文件,给多个PHP进程共享配置数据。
ShareCache
C 版本
通过C来实现共享缓存(共享内存区数据缓存)的话需要在共享内存区中保存哈希表,因为共享内存区是进程中的映射,在不同的进程中其地址可能不同。也就是说,不能通过malloc等调用来实现内存管理了,哈希表中的所用数据的地址都必须通过相对于内存共享区起始地址的偏移量计算得到。我设想了很多的数据保存和查找方案,都能实现Key-Value的查找插入和删除和动态扩容的机制。偶然间,我发现一篇很好的博客,解决了和我一样的问题,不过人家的方案更加健全和完善,在此贴上来,有时间翻译一下。
Shared Memory Hash Table
原网址:https://vhanda.in/blog/2012/07/shared-memory-hash-table/
在过去的一个月里我都在研究如何在共享内存中保存的哈希表,这样就可以很简单的跨进程使用了。在多个进程中缓存简单的数据这是一个很好的想法。我的使用目的主要是Nepomuk Resource class,它通过使用哈希表来优化键值对的缓存。为了保证每个应用的Resource classes之间的一致性,在其中花费了很多的努力。
我总以为这个基本的想法肯定已经有人实现过了,但是我就是找不到真正能支持动态调整大小的共享内存哈希表。
基本的哈希表
哈希可以说是计算机科学中最重要的概念之一了,如果你还不知道它的工作原理,这里有一些很好的链接可以参考:
- Wikipedia Article
- Video lectures from algo-class.org
- [Video lectures from MIT](Video lectures from MIT)
共享内存哈希表
在共享内存区中实现哈希表,会碰到一些列普通哈希表不要处理的问题。在unix环境中,每个共享内存区都有一个唯一的标示,其他的进程通过标示可以访问它。正因为此,我们不能独立的为每个Node/Bucket分配内存。
大多数的哈希表,都是通过链的方式来解决冲突。
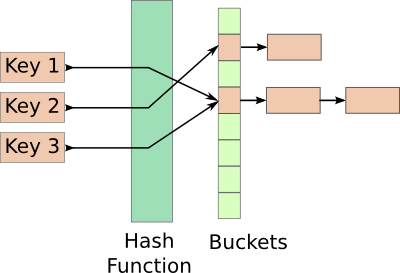
为每个node分配一个新的共享内存区就显得有点夸张了。
结构
所有的数据都得保存在一个连续的内存空间中,因为我们需要的哈希表的结构和一般的就不一样了。
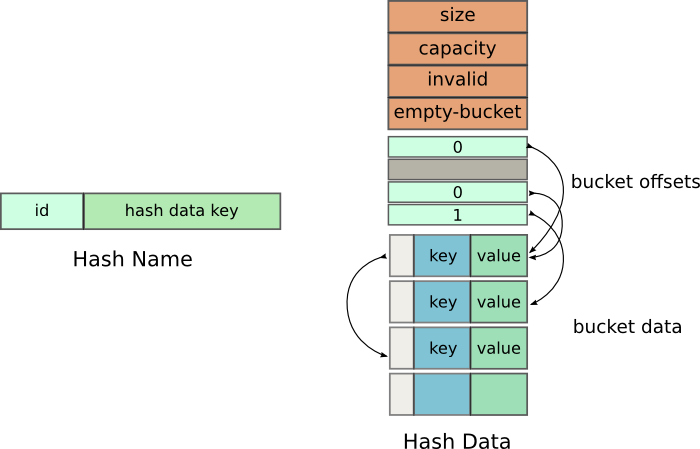
我们使用两个共享内存区-HashName 和 HashData。这么做的目的是因为哈希表的大小不是固定的,它可能需要重新分配大小。在重新分配大小的时候,一个新的共享内存区会被创建,我们需要通知所有的客户程序使用这个新的内存区标示。
HashName只是用来告诉客户唯一标示,而HashData才是我们最终要用的,它随着哈希表大小的变化需要能够改变。
Hash Name 数据

附加的整数是一个小的优化。当客户端需要使用哈希表时,它需要确定它们链接的是恰当的内存区,而不是老的版本。它需要确认自己记录的HashData name和HashName共享内存区记录的是不是一样的。
这需要字符串比较,我能通过附加的整数来暗示这个字符发生了变化。整数的比较比字符串的比较要快很多了。
实际数据
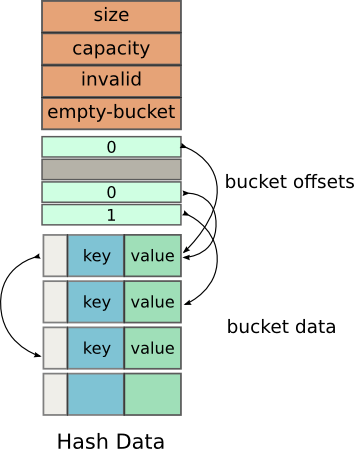
大多数的初始化成员的含义都显而易见,但是我们还是说明一下吧:
- Size: The number of elements in the hash table
- Capacity: The total number of elements the hash table can hold
- Invalid: The number of buckets that invalid (have been deleted)
- Empty-Bucket: The offset of the next empty bucket which may be used for insertion
紧接着这些之后是offsets数组,指向内部的m_buckets。这个数组不像传统的哈希表中的一样存储指向Buckets的指针,保存的是相对于下一个数组开始位置的偏移量。
下一个数组是一个保存Bucket的数组,内部指向m_data。这个数组维护着键值对。Bucket类型定义如下:
struct Bucket {
KeyType key;
ValueType value;
int hash;
int link;
}
2
3
4
5
6
The link member is again not a pointer, but it contains the integer offset to the next Bucket from the start of m_data.
link成员同样不是一个指针,包含的是从m_data开始到下一个Bucket的整数偏移量。
插入
插入操作很简单。key被哈希成一个整型,然后取模后用作索引。
The corresponding index is checked in m_buckets. If m_buckets does not already have some value over there, there is no collision and we just allocate a new Bucket and plug in its offset.
在m_buckets查找相应的index,如果m_buckets在相应的地方没有值,那么就没有冲突发生,
Allocations of new buckets are done by consuming the location given by emptyBucket, and then incrementing its value.
If m_buckets does not have an empty value, we go to the corresponding Bucket, and follow its link until the link is empty. At that point we allocate a new node and make the link point to this new Bucket. This approach is almost identical to that of conventional chaining, except that we are using offsets instead of pointers.
Deletions
Delete operations are fairly similar to insertions. The index is procured by hashing they key, and performing a modulo operation with the capacity. After which m_buckets is used to get the offset of the actual Bucket. Instead of deleting the bucket, which would not be possible cause it is stored in an array, we simply mark it as invalid.
The number of invalid buckets is then updated, and m_buckets[index] is marked as empty. Later during the resize operation, the wasted memory will be cleaned up.
Note: Deletions are actually a little more complex because of collisions, but you just need to traverse the entire link chain, and mark the corresponding Bucket as invalid
Resizing The resize operation occurs when the loadRatio of the hash table goes above a certain threshold. For now, I’ve set it to 0.8.
loadRatio = (invalid-buckets + size) / capacity
When the loadRatio goes above 0.8, a new shared memory location is allocated. The metadata (size, capacity, invalid and empty-Bucket) are initially copied to the new shared memory. After which the offset for each bucket is recalculated ( hash % newCapacity ), and it is inserted into the new shared memory.
The invalid buckets are ignored and they are not copied.
Once the copying is completed, the hash data key in HashName is updated, the id is incremented. This is done so that all other applications using the shared memory can update their internal pointers.
Iterating
Iterating over the hash table is probably the only operation that is a lot simpler than traditional hash tables. We already have all the data listed as an array -m_data. All we need to do is iterate over it while discarding invalid buckets which were created by delete operations.
Well, in theory.
In practice, safely iterating over a shared hash involves copying the element being accessed. Mainly because another application could have shrunk the entire memory and your index could no longer be valid.
Another possible way is to copy its contents to a QHash. I’ve implemented a simple function for that.
Problems
Dynamically allocated Types
You cannot use any types which dynamically allocate memory as the key or value. This rules out QString, QUrl, QVariant (kinda) and most of the commonly used Qt Data Structures. If you need to use a string as the key, you’ll need to explicitly set an upper limit by using something like QVarLengthArray.
This is a huge problem, and makes using the shared hash very difficult in practice.